</p>")
Quantum computers may one day enable revolutionary advances in fluid dynamics, drug discovery, development of better agricultural fertilizers, improved materials design and other technical areas. (Credit: Tim Hynes)
Quantum computers may one day enable revolutionary advances in fluid dynamics, drug discovery, development of better agricultural fertilizers, improved materials design and other technical areas that are beyond the capabilities of today’s conventional computers. To reach those goals, companies from around the world are pursuing a variety of approaches aimed at developing large-scale, fault-tolerant quantum computers.
The approaches of over a dozen quantum computing companies are now being evaluated through the Quantum Benchmarking Initiative (QBI), a project of the U.S. Defense Advanced Research Projects Agency (DARPA). According to the agency, QBI “aims to rigorously verify and validate whether any quantum computing approach can achieve utility-scale operation – meaning its computational value exceeds its cost – by the year 2033.”
Supporting the effort, a 40-person interdisciplinary research team from the Georgia Tech Research Institute (GTRI) has joined the test and evaluation component of QBI, providing unbiased subject-matter experts to work with 13 other research organizations in evaluating the R&D plans of participating quantum computer companies. Through this collaboration, the GTRI team is working with more than 400 other third-party experts on the project.
Read the complete article on the GTRI news site

As students increasingly turn to artificial intelligence (AI) to help with coursework, some worry that their learning could be compromised. Georgia Tech researchers are working to counter this potential decline with an AI tool they hope will promote learning rather than hinder it.
TokenSmith is a citation-supported large language model (LLM) tutor that can be hosted locally on a user’s personal computer. The tutor only provides answers based on course materials, such as the textbook or lecture slides.
Associate Professor Joy Arulraj began the project with support from the Bill Kent Family Foundation AI in Higher Education Faculty Fellowship last year. The fellowship, led by Georgia Tech’s Center for 21st Century Universities, supports faculty projects exploring innovative and ethical uses of AI in teaching.
Arulraj has enlisted assistant professors Kexin Rong and Steve Mussmann to help build TokenSmith.
Mussmann said TokenSmith is a synergistic blend of a database system and a machine learning system. The model stores textbooks, textbook annotations by course staff, common questions and answers, a learning state of the student, and student feedback in a structured database system. However, machine learning plays a key role in the answer generation as well as adapting the system to the student, course staff guidance, and user feedback.
"What excites me most is demonstrating how data-driven ML and principled database systems design can reinforce each other — one providing adaptability and flexibility, the other providing structure and traceability — in a way that benefits students," Mussmann said.
Keeping the model local has been an important focus of the project. The team wanted to create an AI tutor that helps students learn from their class resources rather than just giving answers. With each response, TokenSmith cites the origin of the answer in the provided documents.
“One problem with LLMs is that they can hallucinate and provide wrong answers, but in this controlled environment, we can add these guardrails to make sure it’s actually helpful in an educational setting,” Rong said.
Rong said she feels that students often undervalue textbooks, and she hopes TokenSmith can motivate students to make better use of them.
“Textbooks can sometimes be daunting, but maybe if we combine them with the model, students might be more willing to read a paragraph or page in the textbook, and that could help clarify something for them,” she said.
Running the model locally is more cost-effective and helps preserve the user’s privacy. But running the new tool locally comes with technical challenges.
One challenge with creating the model is speed. Since it is a locally based model, TokenSmith depends solely on the user’s computer memory. Tests have also shown that the tutor currently struggles to answer more complex questions.
“We are interested in pushing the boundaries of these local models so that they give students good answers and also run fast enough to keep students engaged,” Arulraj said.
News Contact
Morgan Usry, Communications Officer


While people use search engines, chatbots, and generative artificial intelligence tools every day, most don’t know how they work. This sets unrealistic expectations for AI and leads to misuse. It also slows progress toward building new AI applications.
Georgia Tech researchers are making AI easier to understand through their work on Transformer Explainer. The free, online tool shows non-experts how ChatGPT, Claude, and other large language models (LLMs) process language.
Transformer Explainer is easy to use and runs on any web browser. It quickly went viral after its debut, reaching 150,000 users in its first three months. More than 563,000 people worldwide have used the tool so far.
Global interest in Transformer Explainer continues when the team presents the tool at the 2026 Conference on Human Factors in Computing Systems (CHI 2026). CHI, the world’s most prestigious conference on human-computer interaction, will take place in Barcelona, April 13-17.
“There are moments when LLMs can seem almost like a person with their own will and personality, and that misperception has real consequences. For example, there have been cases where teenagers have made poor decisions based on conversations with LLMs,” said Ph.D. student Aeree Cho.
“Understanding that an LLM is fundamentally a model that predicts the probability distribution of the next token helps users avoid taking its outputs as absolute. What you put in shapes what comes out, and that understanding helps people engage with AI more carefully and critically.”
A transformer is a neural network architecture that changes data input sequence into an output. Text, audio, and images are forms of processed data, which is why transformers are common in generative AI models. They do this by learning context and tracking mathematical relationships between sequence components.
Transformer Explainer demystifies how transformers work. The platform uses visualization and interaction to show, step by step, how text flows through a model and produces predictions.
Using this approach, Transformer Explainer impacts the AI landscape in four main ways:
- It counters hype and misconceptions surrounding AI by showing how transformers work.
- It improves AI literacy among users by removing technical barriers and lowering the entry for learning about AI.
- It expands AI education by helping instructors teach AI mechanisms without extensive setup or computing resources.
- It influences future development of AI tools and educational techniques by providing a blueprint for interpretable AI systems.
“When I first learned about transformers, I felt overwhelmed. A transformer model has many parts, each with its own complex math. Existing resources typically present all this information at once, making it difficult to see how everything fits together,” said Grace Kim, a dual B.S./M.S. computer science student.
“By leveraging interactive visualization, we use levels of abstraction to first show the big picture of the entire model. Then users click into individual parts to reveal the underlying details and math. This way, Transformer Explainer makes learning far less intimidating.”
Many users don’t know what transformers are or how they work. The Georgia Tech team found that people often misunderstand AI. Some label AI with human-like characteristics, such as creativity. Others even describe it as working like magic.
Furthermore, barriers make it hard for students interested in transformers to start learning. Tutorials tend to be too technical and overwhelm beginners with math and code. While visualization tools exist, these often target more advanced AI experts.
Transformer Explainer overcomes these obstacles through its interactive, user-focused platform. It runs a familiar GPT model directly in any web browser, requiring no installation or special hardware.
Users can enter their own text and watch the model predict the next word in real time. Sankey-style diagrams show how information moves through embeddings, attention heads, and transformer blocks.
The platform also lets users switch between high-level concepts and detailed math. By adjusting temperature settings, users can see how randomness affects predictions. This reveals how probabilities drive AI outputs, rather than creativity.
“Millions of people around the world interact with transformer-driven AI. We believe that it is crucial to bridge the gap between day-to-day user experience and the models' technical reality, ensuring these tools are not misinterpreted as human-like or seen as sentient,” said Ph.D. student Alex Karpekov.
“Explaining the architecture helps users recognize that language generated by models is a product of computation, leading to a more grounded engagement with the technology.”
Cho, Karpekov, and Kim led the development of Transformer Explainer. Ph.D. students Alec Helbling, Seongmin Lee, Ben Hoover, and alumni Zijie (Jay) Wang (Ph.D. ML-CSE 2024) and Minsuk Kahng (Ph.D. CS-CSE 2019) assisted on the project.
Professor Polo Chau supervised the group and their work. His lab focuses on data science, human-centered AI, and visualization for social good.
Acceptance at CHI 2026 stems from the team winning the best poster award at the 2024 IEEE Visualization Conference. This recognition from one of the top venues in visualization research highlights Transformer Explainer’s effectiveness in teaching how transformers work.
“Transformer Explainer has reached over half a million learners worldwide,” said Chau, a faculty member in the School of Computational Science and Engineering.
“I'm thrilled to see it extend Georgia Tech's mission of expanding access to higher education, now to anyone with a web browser.”
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu

Voice-activated, conversational artificial intelligence (AI) agents must provide clear explanations for their suggestions, or older adults aren’t likely to trust them.
That’s one of the main findings from a study by AI Caring on what older adults expect from explainable AI (XAI).
AI Caring is one of three AI Institutions led by Georgia Tech and funded by the National Science Foundation (NSF). The institution supports AI research that benefits older adults and their caregivers.
Niharika Mathur, a Ph.D. candidate in the School of Interactive Computing, was the lead author of a paper based on the study. The paper will be presented in April at the 2026 ACM Conference on Human Factors in Computing Systems (CHI) in Barcelona.
Mathur worked with the Cognitive Empowerment Program at Emory University to interview 23 older adults who live alone and use voice-activated AI assistants like Amazon’s Alexa and Google Home.
Many of them told her they feel excluded from the design of these products.
“The assumption is that all people want interactions the same way and across all kinds of situations, but that isn’t true,” Mathur said. “How older people use AI and what they want from it are different from what younger people prefer.”
One example she gave is that young people tend to be informal when talking with AI. Older people, on the other hand, talk to the agent like they would a person.
“If Older adults are talking to their family members about Alexa, they usually refer to Alexa as ‘she’ instead of ‘it,’” Mathur said. “They tend to humanize these systems a lot more than young people.”
Good Explanations
The study evaluated AI explanations that drew information from four sources of data:
- User history (past conversations with the agent)
- Environmental data (indoor temperature or the weather forecast)
- Activity data (how much time a user spends in different areas of the home)
- Internal reasoning (mathematical probabilities and likely outcomes)
Mathur said older users trust the agent more when it bases its explanations on data from the first three sources. However, internal reasoning creates skepticism.
Internal reasoning means the AI doesn’t have enough data from the other sources to give an explanation. It provides a percentage to reflect its confidence based on what it knows.
“The overwhelming response was negative toward confidence scores,” Mathur said. “If the AI says it’s 92% confident, older adults want to know what that’s based on.”
This is another example that Mathur said points to generational preferences.
“There’s a lot of explainable AI research that shows younger people like to see numbers in explanations, and they also tend to rely too much on explanations that contain numerical confidence. Older adults are the opposite. It makes them trust it less.”
Knowing the Context
Mathur said that AI agents interacting with older adults should serve a dual purpose. They should provide users with companionship and support independence while reducing the caretaking burden often placed on family members.
Some studies have shown that engineers have tended to favor caretakers in the design of these tools. They prioritize daily tasks and routines, leaving some older adults to feel like they are merely a box to be checked.
She discovered that in urgent situations, older users prefer the AI to be straightforward, while in casual settings, they desire more conversation.
“How people interact with technological systems is grounded in what the stakes of the situation are,” she said. “If it had anything to do with their immediate sense of safety, they did not want conversational elaboration. They want the AI to be very direct and factual.”
Not Just Checking Boxes
Mathur said AI agents that interact with older adults are ideally constructed with a dual purpose. They should provide companionship and autonomy for the users while alleviating the burden of caretaking that is often placed on their family members.
Some studies have shown that engineers have strayed toward favoring caretakers in the design of these tools. They prioritize daily tasks and routines, leaving some older adults to feel like they are a box to be checked.
“They’re not being thought of as consumers,” Mathur said. “A lot of products are being made for them but not with them.”
She also said psychological well-being is one of the most important outcomes these tools should produce.
Showing older adults that they are listened to can significantly help in gaining their trust. Some interviewees told Mathur they want agents who are deliberate about understanding their preferences and don’t dismiss their questions.
Meeting these needs reduces the likelihood of protesting and creating conflict with family members.
“It highlights just how important well-designed explanations are,” she said. “We must go beyond a transparency checklist.”
News Contact
Nathan Deen
College of Computing
Georgia Tech

Women in need of supportive maternal and menstrual healthcare in patriarchal societies have increasingly found outlets for disclosure in online communities.
That support, however, begins to disappear in these restrictive cultures once women reach menopause, according to new research from Georgia Tech
Naveena Karusala, an assistant professor in Georgia Tech’s School of Interactive Computing, and master’s student Umme Ammara are working toward improving existing technologies and designing new ones for a demographic they believe has been neglected.
Karusala and Ammara co-authored a paper based on a study they conducted with women in urban Pakistan experiencing menopause.
“Women’s health is understudied in general, but menopause is more neglected than other women’s health issues,” Karusala said. “Our choice to focus on menopause is motivated by expanding how we holistically think about women’s well-being across their lifespan.”
Karusala and Ammara will present their paper in April at the 2026 ACM Conference on Human Factors in Computing Systems (CHI) in Barcelona.
Masking Symptoms
Menopause is diagnosed after 12 consecutive months without a period, vaginal bleeding, or spotting. The transition to menopause, called perimenopause, usually happens over two to eight years.
Hormone changes may cause symptoms such as irregular periods, vaginal dryness, hot flashes, night sweats, trouble sleeping, mood swings, and brain fog.
These symptoms can be debilitating in some cases and affect daily life. However, Ammara said women are pressured to remain silent, maintain appearances, and regulate their emotions to meet social expectations.
“Understanding menopause is important because a woman would be experiencing all these symptoms, and people will not understand those as actual symptoms,” Ammara said. “There’s been resistance to the idea of the medicalization of menopause. People don’t view it as an illness, but as a life transition and something that happens naturally.”
Feeling Isolated
The women interviewed by Karusala and Ammara either stayed at home full-time or were part of the workforce.
The researchers discovered that trusted family members might be the only sources women who stay at home and do not work turn to for disclosure.
“Women at home have the flexibility to take breaks or work at their own pace, so a lot of their experience is shaped by the emotional barriers they face,” Ammara said.
“That could come from their husbands and family members. Some are supportive and some are not. They might weaponize it and use that term against them, or they might dismiss what they’re going through.”
Ammara said it might be easier for women in the workforce to confide in their coworkers, but explaining to an employer that they need sick leave for menopause symptoms can be intimidating.
Even in online communities that have enabled women to anonymously share their health experiences, menopause is seldom discussed.
Raising Awareness
Karusala and Ammara argue in their paper that a public health approach could be the most effective way to spark conversation about menopause in a patriarchal culture in which technology use varies.
They said the challenge in implementing technologies geared toward menopause support is that the condition isn’t well understood in public. Improving maternal health, for example, is easier to promote within these societies because of the general understanding that motherhood is important.
“There must be an existing infrastructure to build on,” Karusala said. “For example, menstrual and maternal health are taught in schools and regularly discussed in primary care. Cultural and social meaning and importance are placed on motherhood.
“A lot of that doesn’t exist for menopause. Primary care doctors are unprepared to talk about menopause compared to other health issues.”
Design Solutions
Ammara said that the most effective way for technologies to make an impact on women going through menopause is to directly address systemic power structures around women’s health within Pakistani culture.
It can start with the husbands.
“Framing the issue for husbands to understand menopause should be at the forefront of designing technology solutions,” she said.
“In Islamic contexts, we suggest using faith-based framings. This has been proposed for maternal health in prior works that draw on Islamic principles to engage expectant fathers in providing care and support. Framing it around religious responsibility to involve men in the journey can also be done for menopause.”
News Contact
Nathan Deen
College of Computing
Georgia Tech

Whether it’s a fire or a flood, a ship’s crew can only rely on itself and its training in emergencies at sea. The same is true for crews facing digital threats on oil tankers, cargo ships, and other commercial vessels.
New cybersecurity research from the Georgia Institute of Technology, however, revealed that crews aboard commercial vessels were often not adequately prepared to manage cyberattacks effectively due to systemic training gaps.
The findings are based on interviews conducted by researchers with more than 20 officer-level mariners to assess the maritime industry’s readiness to handle cybersecurity attacks at sea.
"Historically, cybersecurity research has focused heavily on cyber-physical systems like cars, factories, and industrial plants, but ships have largely been overlooked,” said Anna Raymaker, Ph.D. student and lead researcher.
“That gap is concerning when more than 90% of the world’s goods travel by sea. Recent incidents, from GPS spoofing to ships linked to subsea cable disruptions, show that maritime systems are increasingly part of the global cyber threat landscape.”
The researchers proposed four practical strategies to strengthen maritime cyber defenses and close the training gaps. Their findings were presented recently at the ACM SIGSAC Conference on Computer and Communications Security (CCS).
1. Make Cybersecurity Training Actually Maritime
Many of those interviewed for the study described current cybersecurity training as “boilerplate” — generic modules that don’t reflect real shipboard risks.
Researchers recommend:
- Role-specific instruction: Navigation officers should learn to detect and identify GPS spoofing. Engineers should focus on vulnerabilities in remotely monitored systems.
- Bridging IT and Operational Technology: Crews need to understand how attacks on IT systems can trigger physical consequences in operational technology — including collisions, groundings, or explosions.
- Hands-on delivery: Replace passive PowerPoints with drills and in-person exercises that build muscle memory.
- Accessible standards: Training must account for the wide range of educational backgrounds across crews and be standardized across ranks.
2. Move Beyond “Call IT”
At sea, crews can’t simply escalate a cyber incident to a shore-based IT department and wait. Operational resilience requires onboard readiness.
Researchers recommend:
- Vessel-specific response plans: Ships need clear, actionable protocols for threats such as AIS jamming or radar manipulation.
- Military-style drills: Adopting MCON (Emission Control) exercises — used by the U.S. Military Sealift Command — can train crews to operate safely without electronic systems.
- Stronger connectivity controls: High-bandwidth satellite systems like Starlink introduce new risks. Clear policies and network segregation are essential to prevent new entry points for attackers.
Related Article: When GPS lies at sea: How electronic warfare is threatening ships and their crews by Anna Raymaker
3. Create Unified, Ship-Specific Regulations
Maritime cybersecurity regulations are often reactive and fragmented. Researchers argue the industry needs a cohesive, domain-specific framework.
Key recommendations include:
- A unified global model: Like the energy sector’s NERC CIP standards, a maritime framework could mandate baseline controls such as encryption, network segmentation, and anonymous incident reporting.
- Rules built for real crews: Regulations designed for large naval operations don’t translate well to smaller merchant or research vessels. Standards must reflect actual shipboard conditions.
- Future-proofing requirements: Autonomous ships and remotely operated vessels expand the cyber-physical attack surface. Regulations must proactively address these emerging technologies.
4. Invest in Maritime-Specific Cyber Research
Finally, the researchers stress that long-term resilience requires deeper technical research focused on maritime systems.
Priority areas include:
- Real-time intrusion detection systems tailored to shipboard protocols.
- Proactive security risk assessments of interconnected onboard systems.
- Cyber-physical modeling to better understand cascading failures in complex maritime environments.
The Bottom Line
Cyber threats at sea are no longer hypothetical. Mariners report real-world incidents ranging from GPS spoofing to ransomware that disrupts global trade.
“Through our interviews with mariners, I saw firsthand how much dedication and pride they take in their work,” said Raymaker. “Our goal is for this research to serve as a call to action for researchers, policymakers, and industry to invest more attention in maritime cybersecurity and support the people who risk their lives every day to keep global trade, food, and energy moving."
A Sea of Cyber Threats: Maritime Cybersecurity from the Perspective of Mariners was presented at CCS 2025. It was written by Raymaker and her colleagues, Ph.D. students Akshaya Kumar, Miuyin Yong Wong, and Ryan Pickren; Research Scientist Animesh Chhotaray, Associate Professor Frank Li, Associate Professor Saman Zonouz, and Georgia Tech Provost and Executive Vice President for Academic Affairs Raheem Beyah.
News Contact
John Popham
Communications Officer II School of Cybersecurity and Privacy


The in-state rivalry between the Yellow Jackets and the Bulldogs usually heats up when Georgia Tech visits the University of Georgia. However, one Saturday last month, the focus shifted from competition to collaboration.
The Georgia Scientific Computing Symposium (GSCS) held its annual meeting on February 21 in Athens. Since 2009, the event has hosted researchers from across the Peach State to showcase homegrown advances in scientific computing.
The symposium highlighted Georgia’s reputation as a computing innovation hub. People from around the world come to Georgia universities to lead computing research. By advancing science, engineering, medicine, and technology, their work improves communities at home and abroad.
Faculty and students from Georgia Tech, UGA, Georgia State University, and Emory University presented at the symposium. Georgia Tech participants came from the colleges of Computing, Engineering, and Sciences.
This year’s organizers agreed to meet in Atlanta for the 2027 symposium. Georgia Tech’s School of Computational Science and Engineering (CSE) will host the 19th GSCS.
“From healthcare to computer chip design, scientific computing underpins many of the technological advances we see in our lives,” said Professor Edmond Chow, associate chair of the School of CSE.
“Scientific computing provides the mathematical models, simulations, and data‑driven tools that make modern innovation possible. It allows people to analyze complex systems, test ideas virtually before building them, and make faster, more accurate decisions across nearly every sector of society.”
Professor Haomin Zhou and Assistant Professor Helen Xu delivered two of the symposium’s five plenary talks.
Zhou presented a new method for solving the Schrödinger equation, a landmark equation in quantum mechanics. Drawing inspiration from the mathematics used in generative artificial intelligence models, his approach develops an algorithm that more effectively simulates waves, particle motion, and other physical systems.
Xu focused on improving how computers move and organize data during complex calculations. Her work uses “cache-friendly” layouts that help computers access data more efficiently, boosting performance for scientific and engineering applications.
“Speaking at GSCS was a great opportunity,” Xu said. “The symposium fostered connections within the scientific computing community and gave us a chance to share exciting research.”
The symposium showcased student work through a poster blitz and a poster session. During the blitz, 36 students each had one minute to introduce their research to the full audience. They then shared more details about their research during the poster session.
The student projects showed the range of fields supported by scientific computing. The session also provided attendees with an opportunity to connect and expand their professional networks, helping grow the field’s future impact.
“As an aerospace engineer by training and aspiring computational scientist, GSCS gave me the platform to network with other researchers in the field while showcasing my own research,” said M.S. student Kashvi Mundra.
“I was able to connect with scientists across different disciplines whose work intersects with my own in unexpected ways. Those conversations pushed my thinking beyond my own lab's perspective, helping me see my work on physics-informed machine learning for inverse problems in a broader scientific computing context.”
Georgia Tech students who presented posters included:
Abir Haque (CSE), Massively Parallel Random Phase Approximation Correlation Energy via Lanczos Quadrature
Antonio Varagnolo (CSE), Physics-Enhanced Deep Surrogates for the Phonon Boltzmann Transport Equation
Ben Burns (CSE), Infinite-Dimensional Stein Variational Inference with Derivative-Informed Neural Operators
Ben Wilfong (CSE), Shocks without Shock Capturing; Compressible Flow at 1 quadrillion Degrees of Freedom without Loss of Accuracy
Daniel Vickers (CSE), Highly-Parallel Fluid-Solid Interactions for Compressible Flows
Eric Fowler (CSE), High-Performance Tensor Contractions in Computational Chemistry
Haoran Yan (Math), Understanding Denoising Autoencoders through the Manifold Hypothesis: A Geometric Perspective
Kashvi Mundra (CSE), Autoregressive Multifidelity Neural Surrogate Modeling under Scarce Data Regimes
Sebastián Gutiérrez Hernández (Math/CSE), PDPO: Parametric Density Path Optimization
Vivian Zhang (AE), Multifidelity Operator Inference: Non-Intrusive Reduced Order Modeling from Scarce Data
Xian Mae Hadia (CSE), Data Efficiency of Surrogate Models: Learning Physics Data from Full Field Data vs. Inductive Bias from Approximate PDE Solvers
Xiangming Huang (CSE), Neural Operator Accelerated Evolutionary Strategies for PDE-Constraint Optimization
Zhaiming Shen (Math), Understanding In-Context Learning on Structured Manifolds: Bridging Attention to Kernel Methods
Zhongjie Shi (Math), Towards Understanding Generalization in DP-GD: A Case Study in Training Two-Layer CNNs
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu
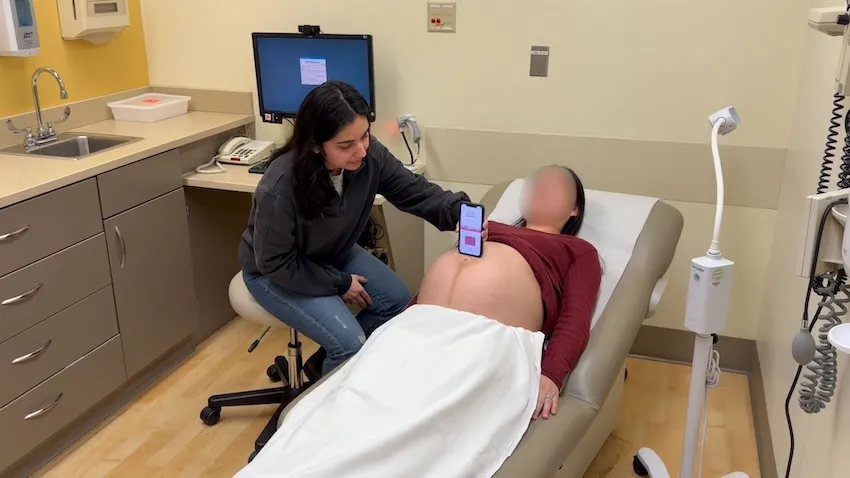
A new mobile app will soon put the ability to monitor a baby’s prenatal heartbeat in the hands of pregnant women who may worry about their baby’s health in between doctor’s visits.
Studies show that one in five pregnant women experiences perinatal anxiety, which is characterized by intense negative thoughts about their pregnancy.
DopFone turns any smartphone speaker into a Doppler radar by emitting a low-pitched ultrasound and detecting reflected signals of abdominal surface vibrations caused by a fetal heartbeat.
Alex Adams, an assistant professor in Georgia Tech’s School of Interactive Computing, said he came up with the idea for DopFone as he and his wife, Elise, experienced two miscarriages. At the time, she couldn’t reliably measure the fetal heart rate with a standard fetal Doppler monitor.
Those experiences exposed gaps in the maternal healthcare process.
“There are a lot of great devices in hospitals and clinics, but there’s not much outside of those venues, even for high-risk pregnancies,” Adams said. “This is about filling the gaps between checkups.”
Poojita Garg joined Adams to work on DopFone while completing her master’s degree at Georgia Tech. She is now pursuing her Ph.D. at the University of Washington and is co-advised by Professor Swetak Patel, who earned his Ph.D. from Georgia Tech in 2008.
Garg is working with the University of Washington School of Medicine to conduct DopFone’s first clinical trials.
Garg tested DopFone on 23 patients and achieved a plus-minus of 4.9 beats per minute, well within the clinical standard range of eight beats per minute for reliable fetal heart rate measurement.
Adams said it measured within two beats per minute in most cases, with an error rate of less than one percent.
About one million pregnancies in the U.S. end in miscarriage, according to a study from the Yale School of Medicine, and doctors know little about what causes them. Adams said that number is probably higher because many go unreported.
Adams and Garg said it’s unclear whether the innovation could reduce the number of miscarriages. However, consistent fetal heart rate data collection outside of the doctor’s office could provide a better idea of what happens leading up to a miscarriage.
“From there, we can take preventative action,” Adams said. “If nothing else, we can give a sense of comfort to those who may be worried.”
Expanding Access
While couples can purchase portable fetal heart rate monitors, Adams and Garg see DopFone as a low-cost alternative for those who live in areas with limited or inaccessible healthcare systems.
“There’s a lot of potential for using it in what doctors like to call maternity deserts,” Garg said. “These are areas where a pregnant person, at the time of delivery, would have to travel long distances to reach a hospital. This technology will be useful globally in underdeveloped areas of the world.”
The researchers also mentioned that external add-ons and attachments aren’t part of their design goals. They prefer to rely on the phone’s built-in features to keep the technology accessible.
“The real value is that 96% of America already has the technology in their pocket, along with 60% of the world’s population,” Adams said. “Half of the battle is having the right tools. The more we can get from what’s already in the phone, the more we can guarantee people have access to it.”
Not a Substitute
Some patients may feel a constant need to check their unborn child’s heart rate, and Garg acknowledged that a tool like DopFone could increase that anxiety. She and Adams said a future version of the app will tell the parent if the heart rate is within a healthy range.
“There’s a lot of tradeoffs between a tool that could provide reassurance or create anxiety,” she said. “We want the use of this tool to be recommended by a doctor and for doctors and their care teams to be kept in the loop.”
She also said DopFone is not meant to replace anything that is done in a clinic.
“There are devices that make the whole process possible at home, but this is something that should be done in a clinic, so that’s the line we want to draw,” she said.

Two Georgia Tech undergraduates are being recognized for their contributions to computing research.
Ryan Punamiya (CS 2025) and Summer Abramson, a third-year computational media student, have been honored by the Computing Research Association (CRA) through its 2025–2026 Outstanding Undergraduate Researcher Award (URA) program.
Punamiya was named a runner-up for the prestigious award, while Abramson received an honorable mention among hundreds of applicants from universities across North America.
The CRA Outstanding Undergraduate Researcher Award program recognized eight awardees in 2026, along with eight runners-up, nine finalists, and over 200 honorable mentions from thousands of applications.
Advancing Robotics Research
Punamiya knew early on that he didn’t want to wait until starting his Ph.D. to do meaningful and impactful robotics research.
Punamiya joined the Robot Learning and Reasoning Lab (RL2) directed by Assistant Professor Danfei Xu. While there, he contributed to the lab’s Meta-sponsored EgoMimic project, which trains robots to perform human tasks using recordings captured by Meta’s Project Aria research glasses.
Punamiya is also the first author of a paper accepted to the 2025 Conference on Neural Information Processing Systems (NeurIPS), one of the world’s most prestigious artificial intelligence (AI) and machine learning conferences.
“Ryan is the strongest undergraduate I've worked with,” Xu said, “including students who went on to Stanford, Berkeley, and leadership roles in major tech companies. He’s already operating at the level of a strong third-year Ph.D. student.”
Punamiya said it was a challenge to balance his undergraduate coursework with his research in Xu’s lab.
“You get out how much you put in,” he said. “I built my class schedule to give myself as much time to do research as possible. It also boils down to having the right research mentors.
“(Xu) never saw me as an undergrad who’s just there to do grunt work. I was fortunate he saw my curiosity and cultivated me as a researcher. That’s really how you get more undergrads motivated to research — giving them the chance to be independent and explore ideas of their own.”
Punamiya said his work in Xu’s lab has already helped him identify the research areas he wants to focus on as he considers his next steps. He will continue developing generalized training models for robots using human data so they can perform tasks instantly upon deployment.
"The amount of data needed to train a robot is difficult to obtain even for top industry companies," he said. "We have embodied robot data available in billions of humans. With the advent of extended reality devices, we can get a scalable source of diverse interactions within environments."
Punamiya graduated in December and recently started an internship at Nvidia. He mentioned he has been accepted into several Ph.D. programs, including Georgia Tech, and he is choosing where to continue his research.
“It’s the first time my research has been acknowledged externally by the robotics community,” he said. “It’s good to know the problem I’m working on is important, and that motivates me. Robotics is an exciting field. We are doing things now that two years ago were difficult to do.”
Researching Inclusion in Computing Education
Abramson conducts research in the People-Agents Research for Computing Education (PARCE) Laboratory under the mentorship of Pedro Guillermo Feijóo-García, a faculty member in the School of Computing Instruction. He and the Associate Dean for Undergraduate Education, Olufisayo Omojokun, nominated her for the award.
Her work focuses on the intersection of computing education and human-AI interaction, where she’s been exploring ways to create more equitable technology.
“This is such a huge milestone, and I couldn't be prouder of Summer,” Feijóo-García said. “Mentoring her for almost two years has been an amazing experience.”
Abramson has received the Georgia Tech President’s Undergraduate Research Award (PURA) twice, which supports her research exploring how user-centered design curricula can help address attrition among women in computing.
“I’ve had the amazing opportunity to pursue research at the intersection of student identity, community belonging, and how we can build tools that support our diverse student population,” Abramson said.
“Dr. Pedro and I have a goal to build community through a human-first approach, and I could not be more grateful for his support and guidance in my own journey. The CRA highlights the best of what the computing discipline has to offer, and I am incredibly honored for our work to be recognized.”
Abramson will spend the summer researching how user-centered design curricula can help promote confidence, belonging, and retention for women in computing.
Nominees for the PURA program were recognized for contributing to multiple research projects, authoring or coauthoring papers, presenting at conferences, developing widely used software artifacts, and supporting their communities as teaching assistants, tutors, and mentors.
School of Computing Instruction Communications Officer Emily Smith contributed to this story.
Main Photo: Ryan Punamiya works with a robot during the 2025 International Conference on Robotics and Automation in Atlanta. Photo by Terence Rushin/College of Computing.



Georgia Tech researchers applied their expertise to a national research program that will shape the future of computing. Their work may yield more energy-efficient computers and better predictions for environmental challenges like carbon storage, tsunamis, wildfires, and sustainable energy.
The Department of Energy Office of Science recently released two reports through its Advanced Scientific Computing Research (ASCR) program. The reports were produced by workshops that brought together researchers from universities, national labs, government, and industry to set priorities for scientific computing.
Professor Felix Herrmann served on the organizing committee for the Workshop on Inverse Methods for Complex Systems under Uncertainty. Assistant Professor Peng Chen joined Herrmann as a workshop participant, contributing expertise in data science and machine learning.
Inverse methods work backward from outcomes to find their causes. Scientists use these tools to study complex systems, like designing new materials with targeted properties and using past wildfires to map vulnerable areas and behavior of future fires.
The ASCR report highlighted Herrmann’s work on seismic exploration and monitoring through digital twins. Founded on inverse methods, digital twins upgrade from static models to virtual systems that accurately mirror their physical counterparts.
Digital twins integrate real-time data sources, including fluid flows, monitoring and control systems, risk assessments, and human decisions. These models also account for uncertainty and address data gaps or limitations.
The DOE organized the workshop to support the growing role of inverse modeling. The group identified four priority research directions (PRDs) to guide future work. The PRDs are:
- PRD 1: Discovering, exploiting, and preserving structure
- PRD 2: Identifying and overcoming model limitations
- PRD 3: Integrating disparate multimodal and/or dynamic data
- PRD 4: Solving goal-oriented inverse problems for downstream tasks
“A digital twin is a system you can control, like to optimize operations or to minimize risk,” said Herrmann, who holds joint appointments in the Schools of Earth and Atmospheric Sciences, Electrical and Computer Engineering, and Computational Science and Engineering.
“Digital twins give you a principled way to consider uncertainties, which there are a lot in subsurface monitoring. If you inject carbon dioxide too fast, you will will increase the pressure and may fracture the rock. If you inject too slow, then the process may become too costly. Digital twins help us make balanced decisions under uncertainty.”
Supercomputers, algorithms, and artificial intelligence now power modern science. However, these tools consume enormous amounts of energy. This raises concerns about how to sustain computing and scientific research as we know them in the decades ahead.
Professors Rich Vuduc and Hyesoon Kim co-authored the report from the Workshop on Energy-Efficient Computing for Science. At the three-day ASCR workshop, participants identified five key research directions:
- PRD 1: Co-design energy-efficient hardware devices and architectures for important workloads
- PRD 2: Define the algorithmic foundations of energy-efficient scientific computing
- PRD 3: Reconceptualize software ecosystems for energy efficiency
- PRD 4: Enable energy-efficient data management for data centers, instruments, and users
- PRD 5: Develop integrated, scalable energy measurement and modeling capabilities for next-generation computing systems
“I’m cautiously optimistic about the future of energy-efficient computing. The ASCR report says, from a technological point of view, there are things we can do,” said Vuduc.
“The report lays out paths for how we might design better apps, hardware systems, and algorithms that will use less energy. This is recognition that we should think about how architectures and software work together to drive down energy usage for systems.”
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu