
An Adobe Stock AI-generated image of Socrates, sculpted in marble, looking contemplatively at a laptop.

CS Professor Santosh Vempala is a co-author of a recent research study that explores the role current training and evaluation protocols play in causing LLMs to hallucinate. Photo by Terence Rushin/College of Computing
Although developed by some of the brightest minds of the 21st century, AI-powered large language models (LLMs) could learn something from one of the greatest minds of the 1st century BCE.
Socrates, widely regarded as the founder of Western philosophy, declared, "I know that I know nothing." This simple statement highlights the wisdom of acknowledging the limits of one's own knowledge.
A simple statement, yes, but like some people, LLMs struggle with saying “I don’t know.” In fact, LLMs often can't admit that they don't know something because of the way they are trained, according to a research team that includes a Georgia Tech computer science (CS) professor.
Pre-training LLMs involves them learning to predict the next word correctly by training on massive datasets of text, images, or other data. Models are evaluated and adjusted based on their performance against standard benchmarks, which are "rewarded" for preferred outputs or answers.
Current evaluation protocols, however, penalize non-responses the same as incorrect answers and do not include an "I don't know" option.
According to CS Professor Santosh Vempala, these pre- and post-training shortcomings are what lead LLMs to provide seemingly plausible but false responses known as hallucinations.
Vempala is a co-author of Why Language Models Hallucinate, a research study from OpenAI and Georgia Tech, released in September. He says that there is a direct correlation between an LLM's hallucination rate and its misclassification rate regarding the validity of a given response.
"This means that if the model can't tell fact from fiction, it will hallucinate," Vempala said.
"The problem persists in modern post-training methods for alignment, which are based on evaluation benchmarks that penalize 'I don't know' as much as wrong answers."
Because of the penalties for knowing that it knows nothing – to paraphrase Socrates – guessing is a more rewarding option for current LLMs than admitting uncertainty or ignorance.
The research incorporates and builds on prior work from Vempala and Adam Kalai, an OpenAI researcher and lead author of the current paper. Their earlier work found that LLM hallucinations are mathematically unavoidable for arbitrary facts, given current training methodologies.
"We've been talking about this for about two years. One corollary of our paper is that, for arbitrary facts, despite being trained only on valid data, the hallucination rate is determined by the fraction of missing facts in the training data," said Vempala, Frederick Storey II Chair of Computing and professor in the School of CS.
To illustrate this point, imagine you have a huge Pokémon card collection. Pikachu is so familiar that you can confidently describe its moves and abilities. However, accurately remembering facts about Pikachu Libre, an extremely rare card, would likely be more difficult.
“More to the point, if your collection has a large fraction of unique cards, then it is likely that you are still missing a large fraction of the overall set of cards. This is known as the Good-Turing estimate,” Vempala said.
[OpenAI Blog: Why Language Models Hallucinate]
According to Kalai and Vempala, the same is true for LLMs based on current training protocols.
“Think about country capitals,” Kalai said. “They all appear many times in the training data, so language models don’t tend to hallucinate on those.
“On the other hand, think about the birthdays of people’s pets. When those are mentioned in the training data, it may just be once.
“So, pre-trained language models will hallucinate on those. However, post-training can and should teach the model not to guess randomly on facts like those.”
Vempala thinks tinkering with pre-training methods could be risky because, overall, they work well and deliver accurate results. However, he and his co-authors offered suggestions for reducing the occurrence of hallucinations with changes to the evaluation and post-training process.
Among the team's recommended changes is that more value be placed on the accuracy of an LLM's responses rather than on how comprehensive their responses are. The team also suggests implementing what it refers to as “behavioral calibration.”
Using this methodology, LLMs would only answer if their confidence level exceeds target thresholds. These thresholds would be tuned for different user domains and prompts. They would also appropriately reduce penalties for “I don’t know” responses, along with appropriate expressions of uncertainty and wrong answers.
Vempala believes that implementing some of these modifications could result in LLMs that are trained to be more cautious and truthful. This shift could lead to more intelligent systems in the future that can handle nuanced, real-world conversations more effectively.
"We hope our recommendations will lead to more trustworthy AI," said Vempala. "However, implementing these modifications to how LLMs are currently evaluated will require acceptance and support from AI companies and users."
News Contact
Ben Snedeker, Comms. Mgr. II
Georgia Tech College of Computing
albert.snedeker@cc.gatech.edu

Two Georgia Tech Ph.D. students created a student-run, faculty-graded, fully-accredited course that links math, engineering and machine learning.
Andrew Rosemberg, with assistance from Michael Klamkin, both student researchers with the U.S. National Science Foundation AI Research Institute for Advances in Optimization (AI4OPT), designed the course to bridge gaps they saw in existing classrooms.
“While Georgia Tech offers excellent courses on optimization, control, and learning, we found no single class that connected all these fields in a cohesive way,” Rosemberg said. “In our research, it was clear these topics are deeply interconnected.”
Problem-driven learning
The course starts with fundamental problems and works backward to the methods required to solve them. Rosemberg said this approach was intentional. He said that courses often center around methods in isolation rather than showing how the methods contribute to the larger context. This keeps the course focused on problem-driven discovery.
The class also serves as a way for Rosemberg and Klamkin to strengthen their own teaching and mentoring skills.
Goals and structure
The primary goal of the course is to help students build a clear understanding of how mathematical programming, classical optimal control, and machine learning techniques such as reinforcement learning connect to one another. Students are also working to produce a structured book by the end of the semester.
“The hope is that this resource will not only solidify our own learning but also serve as a guide for other students who want to approach these problems in the future,” Rosemberg said.
Responsibilities are distributed across participants, with each student delivering lectures, reviewing peers’ work, and contributing to collective discussions. Rosemberg and Klamkin provide additional support where needed, while faculty mentor and director of AI4OPT, Pascal Van Hentenryck, ensures the class stays aligned with broader academic objectives.
Student ownership and collaboration
Rosemberg noted that the student-led model gives students a deeper sense of ownership, making them responsible for their own learning, and having a stronger impact. This model allows students to determine what to learn and why, which promotes critical thinking.
The course uses GitHub as its primary workflow platform. Rosemberg said adds transparency and prepares students for real-world research practices.
“GitHub functions much like university systems such as Canvas or Piazza. It also has the added benefit of making all contributions visible to the world,” Rosemberg explained. “This helps students take pride and ownership of their work, while also introducing them to Git, an essential tool for software development and modern STEM research.”
Emerging insights and challenges
Students have begun aligning their research with course themes, including shaping qualifying exam topics around the intersections of operations research, optimal control and reinforcement learning. Rosemberg said exploring the comparative strengths of these fields side by side has been one of the most rewarding outcomes.
Balancing independence with guidance has proven to be the greatest challenge. He said they have been evolving alongside the students in real time and have learned to emphasize mutual responsibility to promote the collective progress of the class.
Looking ahead
Rosemberg said future iterations of the course may place more emphasis on setting expectations early, given the effort required to deliver a lecture in this format.
His advice for others who may want to replicate the model is to focus on building a committed core team.
“Start with a small, motivated group,” Rosemberg said. “Like a startup, success depends less on the structure and more on the dedication of the people involved.”
News Contact
Jaci Bjorne

Chris Gaffney

By Chris Gaffney, Managing Director, Georgia Tech Supply Chain and Logistics Institute | Supply Chain Advisor | Former Executive at Frito-Lay, AJC International, and Coca-Cola
Introduction
This year has felt like a lifetime in the Generative AI (GenAI) world. Tools, capabilities, and best practices are shifting monthly, sometimes weekly. For supply chain professionals, the message is clear: ongoing development is not optional. Like lean, analytics, or S&OP in prior decades, GenAI proficiency is quickly becoming a differentiator. The question is not if you’ll integrate GenAI into your workflow, but how quickly and effectively.
The Evolution of GenAI in 2025
When we look back to January, it’s striking how much progress has been made in less than a year. Early in 2025, the conversation centered on agentic AI and larger models. GPT-5 and Claude 4 improved reasoning and context windows, while OpenAI introduced ChatGPT Agent in preview, able to carry out bounded multi-step tasks like retrieving files, browsing the web, and drafting structured outputs. In supply chain, this translated into early experiments with automating shipment steps or running contract reviews in a single query — tasks that were pilot-level at best in January.
By mid-year, multimodal capabilities and enterprise copilots began shifting from concept to daily use. Users could combine text, image, and voice inputs to detect defects or summarize complex documents, and copilots became embedded inside SAP, Oracle, Microsoft, and Google platforms. For the first time, GenAI wasn’t just a tool "off to the side" but something integrated directly into the systems supply chain professionals rely on.
In the second half of the year, new capabilities started layering on: memory, specialized small models, and synthetic data with digital twins. Memory allowed copilots to recall context from prior chats or S&OP cycles, reducing rework. Domain-tuned models made GenAI lighter, cheaper, and faster for logistics, procurement, and planning tasks. And digital twin integration allowed organizations to stress-test networks under disruption scenarios, from weather to labor shortages.
Enterprises also moved closer to operations with AI at the edge, using IoT data for predictive maintenance or real-time routing. At the same time, guardrails and compliance became a central topic, with more organizations creating clear "green/yellow/red" tiers for safe use. And in Q4, collaboration AI and hybrid architectures came to the forefront — copilots that can negotiate contracts in multiple languages, and architectures that blend closed and open-source models to balance sovereignty, cost, and security.
For mainstream individual users, the picture is simpler but still powerful. Anyone with ChatGPT Plus or Copilot today can take advantage of:
- Memory and custom instructions to save preferences and formats across sessions.
- Project-only memory (rolling out) to organize work by context.
- Agent previews like Operator to see how automation might work on bounded tasks.
- Connectors and file uploads to bring internal data into conversations.
For leaders, the focus is on policy, safe pilots, and scaling. They are:
- Sponsoring agent experiments in low-risk domains (like supplier alerts).
- Embedding copilots in enterprise systems for daily planning and reporting.
- Formalizing AI use policies so employees know what’s encouraged, conditional, and off-limits.
The net result: what started in January as experimentation has, by October, become a layered landscape. Individual users now have practical tools to reclaim time, while leaders are piloting more ambitious integrations and building the governance to make adoption sustainable.
1. Action Planning is Critical
The pace of change makes a one-and-done training activity insufficient. Think of GenAI skills like fitness: it requires steady reps over time. Professionals who set quarterly development goals — experimenting with new tools, building prompt libraries, testing workflows — will not only stay current but pull ahead.
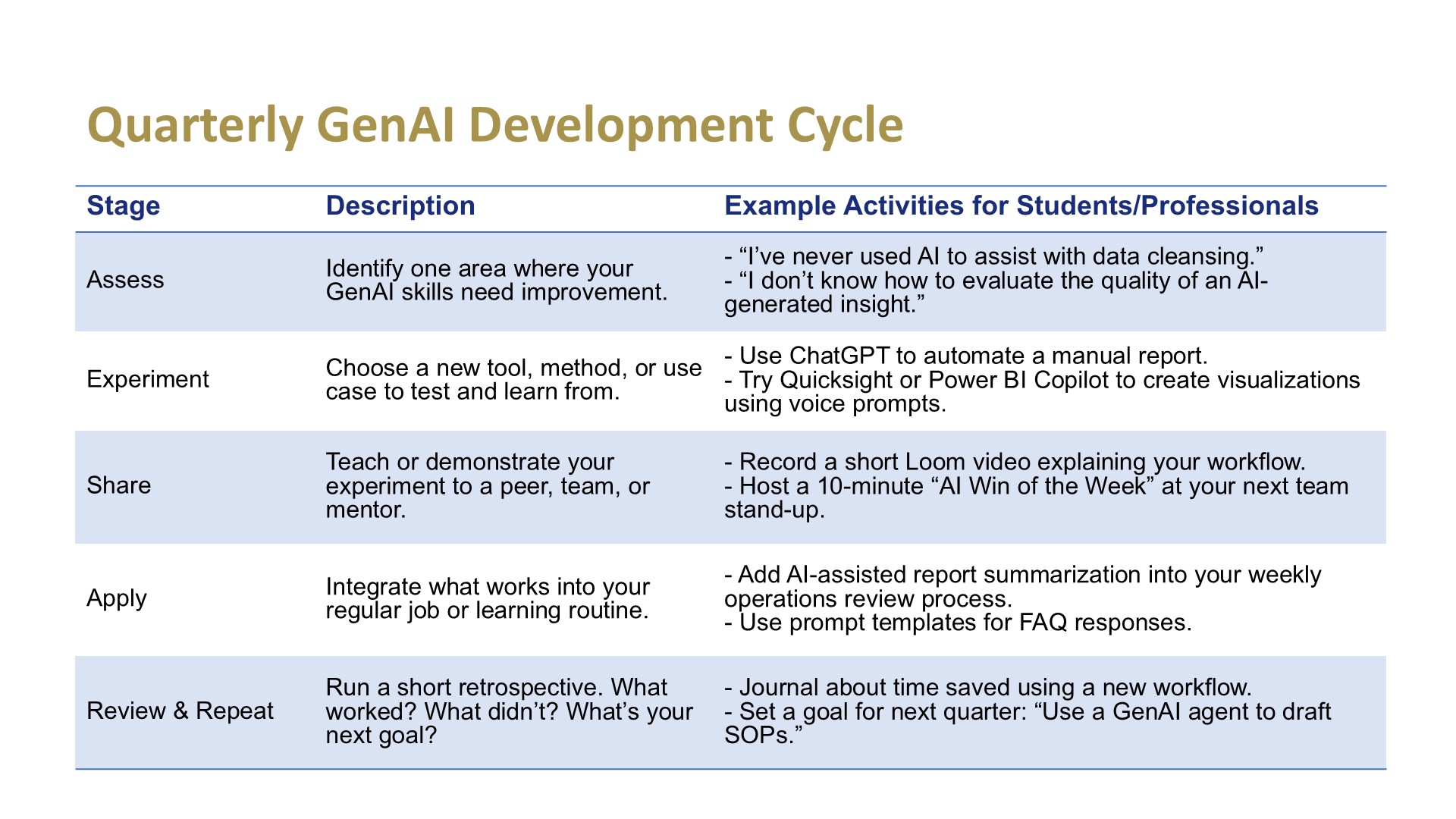
💡 Try This Quarter:
- Build a custom prompt library for routine tasks (e.g., supplier follow-ups, KPI summaries).
- Test one open-source tool such as LangChain or Haystack.
- Use AI to summarize two recent meetings and validate output with your notes.
2. Prompt Maturity is the New Literacy
I’ve personally learned the most about prompting by asking ChatGPT to critique my style against a 12-step framework. The feedback gave me a process improvement plan I still use today. Prompt maturity isn’t abstract — it’s a measurable, improvable skill.
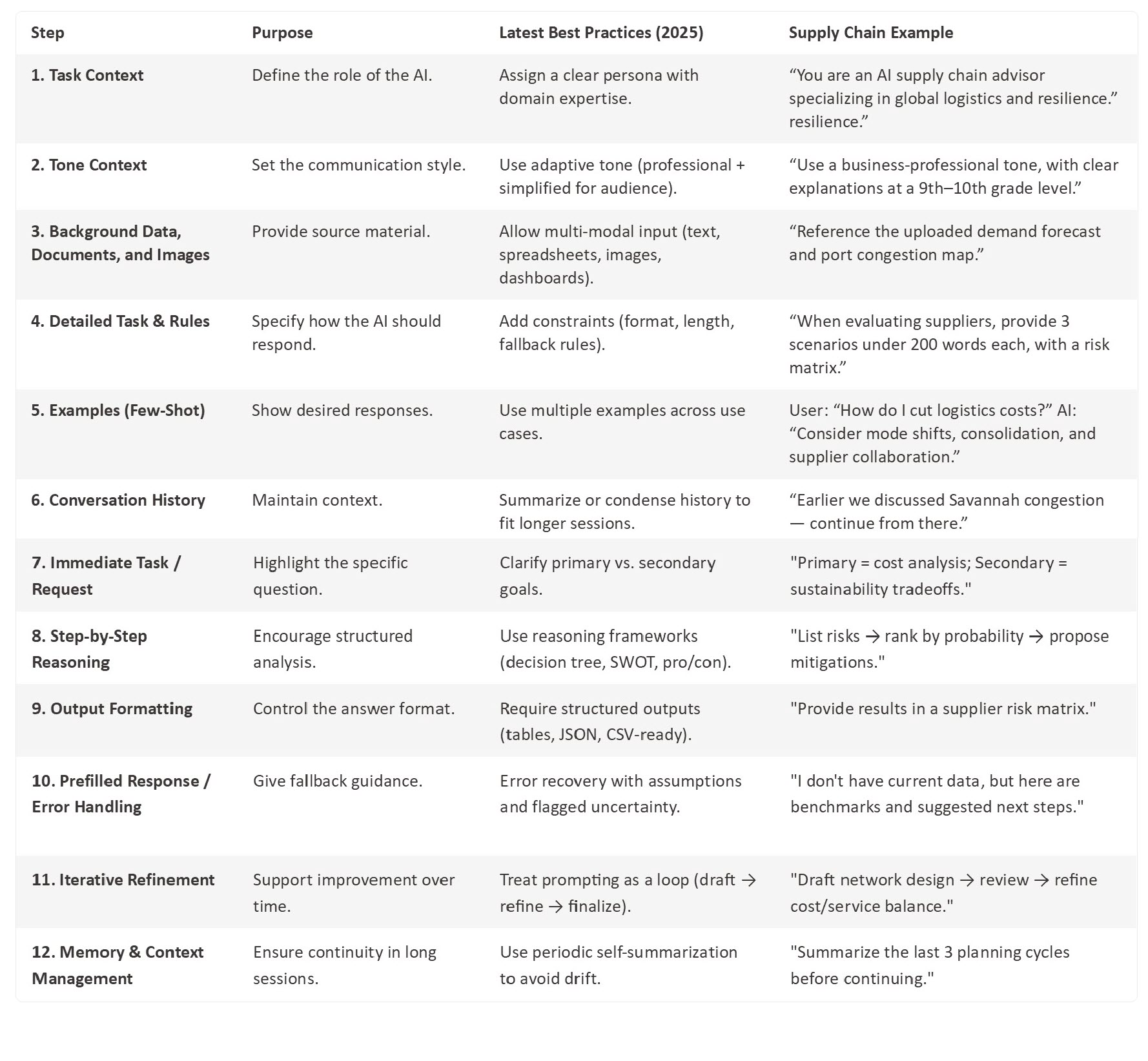
💡 Applied step: Rewrite one work prompt per week by climbing the ladder.
3. Unlocking Personal Productivity
One of the fastest returns from GenAI comes from personal productivity. In our short courses this year, I’ve seen learners gain comfort and lower stress as they practice more with the tools. Many reclaimed time by using GenAI for emails, presentations, meeting notes, and data prep.
While the list of GenAI time-saving strategies is broad, some uses are already mainstream and validated by thousands of professionals. The table below organizes these strategies into categories, provides guidance on how to accomplish them, and highlights common watch-outs to ensure they deliver value without risk.

💡 Try this week: Track one workflow where AI saved time and estimate the hours reclaimed.
4. Critical Thinking: Ironically More Important than Ever
We wrote about critical thinking and added it to our curriculum after studies raised concerns about overreliance on AI. The smarter the tools become, the more important it is to validate their outputs.

💡 Applied step: Take one AI output this week and run it through the checklist — you’ll see both strengths and blind spots.
5. Advocating for Strategy and Guardrails
We’ve seen firsthand how AI policies can evolve. One major retailer shifted in less than a year from a rigid “only data scientists experiment” model to encouraging all employees to try safe versions of multiple LLMs. This shift shows why professionals should advocate for strategy and guardrails that evolve with the technology.
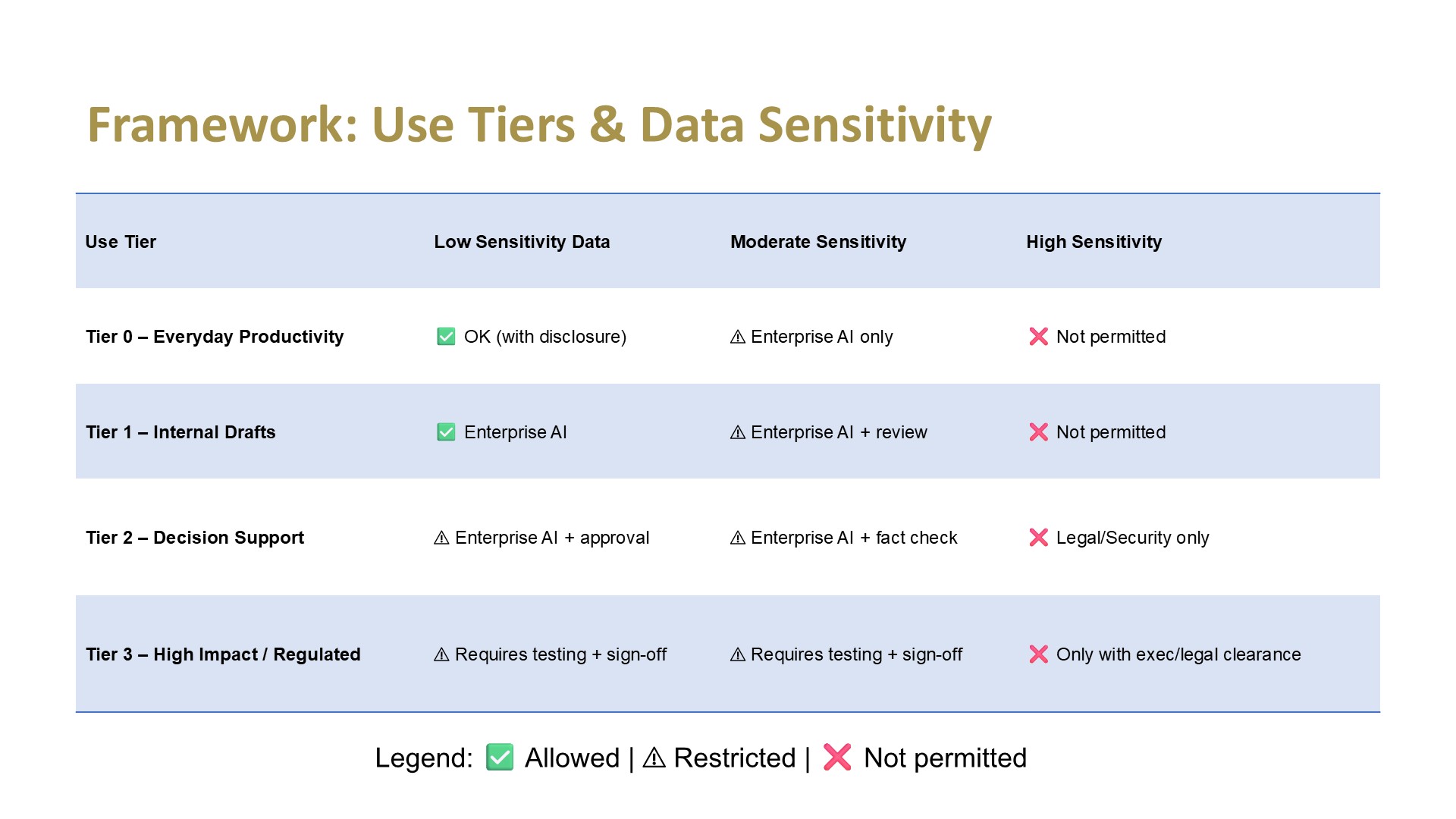
💡 Ask your manager: Which of our daily tasks fall into green, yellow, and red today?
6. Agents: Early but Essential
Many industry partners are actively testing agents. Our software partners are hitting singles and doubles now, with bigger “home run” opportunities still developing. Agents aren’t fully reliable yet, but they are advancing quickly and will increasingly appear in ERP, TMS, and WMS platforms.
In practice, most organizations today sit between Level 1 (Exploratory) and Level 2 (Task-Specific Agents), with early pilots pushing into Level 3 (Augmented Workflows). Tech-forward enterprises — particularly in retail, e-commerce, and global manufacturing — are building domain-specific agents for forecasting, procurement support, and transportation planning, often embedded inside ERP or planning platforms. These companies are experimenting with multi-agent coordination but keep humans firmly in the loop. By contrast, mainstream companies are still largely in the exploratory stage: individuals using general copilots for drafting documents or ad hoc analysis, without enterprise integration, security controls, or governance. The gap is widening — forward-leaning firms are developing playbooks for orchestrated workflows, while many organizations are just beginning to set policies and figure out where AI fits safely into their operations.

Looking ahead, Level 4 (Collaborative Automation) is where the near-term breakthroughs will happen. In the next 3–5 years, we can expect multi-agent orchestration to become a practical tool for managing recurring disruptions — think transportation rerouting during weather events or automated supplier alerts when delivery milestones are missed. Early adoption will occur in large, tech-forward enterprises with strong governance and secure infrastructure. Level 5 (Autonomous Resilience) remains aspirational: while the vision of end-to-end supply chain automation is compelling, regulatory hurdles, trust, and explainability challenges mean human oversight will remain essential. The more realistic trajectory is that enterprises will selectively automate narrow disruption scenarios while maintaining tight human control, with broader autonomy coming only as governance, standards, and trust mechanisms mature.
💡 Applied step: Identify one repetitive process in your work that could be a candidate for an agent.
7. Human in the Loop: Non-Negotiable
Competition has improved model quality this year — but hallucinations and memory issues remain. That’s why “human in the loop” is not just a principle; it’s operational reality. AI is still an assistant, not a replacement.
💡 Applied step: Write down one checkpoint you always apply before sharing AI outputs.
Conclusion
These observations — from teaching courses, updating curriculum, and watching partners experiment — motivated this article. GenAI is evolving at extraordinary speed, and our profession must evolve with it. Build your plan, refine your prompts, reclaim time, apply critical thinking, advocate for strategy, explore agents, and always keep the human in the loop. Those who do will thrive in 2026 and beyond.

Saad Bhamla, associate professor in Georgia Tech's School of Chemical and Biomolecular Engineering
Saad Bhamla of Georgia Tech’s School of Chemical and Biomolecular Engineering (ChBE) is a member of a global cohort of eight scientists and engineers who were named Schmidt Polymaths. They will each receive up to $2.5 million over five years to pursue research in new disciplines or using new methodologies, Schmidt Sciences announced today.
As Schmidt Polymaths, the researchers pursue new approaches compared to previous work. The new cohort of polymaths will answer questions like how to expand access to healthcare with low-cost technologies, what happens to our chromosomes when we age and how to create more accurate computer simulations of climate.
Bhamla, associate professor in ChBE@GT, is the first Schmidt Polymath from Georgia Tech. He will develop low-cost technologies to tackle planetary-scale challenges, including AI-enabled point-of-care diagnostics in low-resource environments, and he will also engineer autonomous morphing machines that adapt, evolve and learn like living systems.
The eight selected scientists represent the fifth cohort of the highly selective Schmidt Polymaths program. Awardees must have been tenured—or achieved similar status—within the previous three years. Previous cohorts have used the award to design new sensor devices, perform experiments at atomic resolutions, analyze trees of life with faster and more efficient algorithms, discover new mathematical formulas assisted by AI, and more.
Drawn from universities worldwide and selected through a competitive application process, Schmidt Polymaths are required to demonstrate past ability and future potential to pursue early-stage, novel research that would otherwise be challenging to fund—even without the current dramatic declines in U.S. funding for science.
“Our world is one deeply interconnected system---but to study it more deeply, we’ve divided it into increasingly narrow categories,” said Wendy Schmidt, who co-founded Schmidt Sciences with her husband Eric. “Schmidt Polymaths see the bigger picture, pursue answers beyond boundaries and expand the edges of what’s possible. Their work can help steer us all toward a healthier future, for people and the planet.”
About Schmidt Sciences
Schmidt Sciences is a nonprofit organization founded in 2024 by Eric and Wendy Schmidt that works to accelerate scientific knowledge and breakthroughs with the most promising, advanced tools to support a thriving planet. The organization prioritizes research in areas poised for impact including AI and advanced computing, astrophysics, biosciences, climate, and space—as well as supporting researchers in a variety of disciplines through its science systems program.
RELATED: Forbes featured Bhamla in the article: Saad Bhamla Is A Polymath
News Contact
Brad Dixon, braddixon@gatech.edu

Professor Jun Ueda with a student in his lab
Robotic systems are currently deployed in sectors ranging from industrial manufacturing to healthcare to agriculture, adding benefits in production times, patient outcomes, and yields. This trend towards greater automation and human robot collaborative work environments, while providing great opportunities, also highlights a critical gap in cybersecurity research. These systems rely on network communication to coordinate movement, meaning that security breaches could result in the robot acting in ways that may endanger people and property.
Current cybersecurity approaches have been shown to be insufficient in blocking sophisticated attacks aimed at networked robotic motion-control systems.
To address this gap, Jun Ueda, Professor and ASME Fellow in the George W. Woodruff School of Mechanical Engineering at Georgia Tech, has been awarded approximately $700,000 by the National Science Foundation to establish methods to enhance cybersecurity for networked motion-control system. The research will focus on the unique geometric vulnerabilities in networked robotic systems and stealthy false data injection attacks that exploit geometric coordinate transformations to maintain mathematical consistency in robotic dynamics while altering physical world behavior.
Using an interdisciplinary approach that will combine research methodology from system dynamics, control, communication, differential geometry and cybersecurity engineering, Ueda hopes to establish new mathematical tools for analyzing robotic security and develop safer networked robotic systems that successfully repel system intrusion, manipulation attacks, and attacks that mislead operators.
This article refers to NSF Program Foundational Research in Robotics (FRR) Award # 2112793
A Geometric Approach for Generalized Encrypted Control of Networked Dynamical Systems
News Contact

Graphic Representation of networked system: Adobe Stock
A recently awarded $20 million NSF Nexus Supercomputer grant to Georgia Tech and partner institutes promises to bring incredible computing power to the CODA building. But what makes this supercomputer different and how will it impact research in labs on campus, across disciplinary units, and across institutions?
Purpose Built for AI Discovery
Nexus is Georgia Tech’s next-generation supercomputer, replacing the HIVE. Most operational high-performance computing systems utilized for research were designed before the explosion in Machine Learning and AI. This revolution has already shown successes for scientific research and data analysis in many domains, but the compute power, complex connectivity, and data storage needs for these systems have limited their access to the academic research community. The Nexus supercomputer design process retained a robust HPC system as a base while integrating artificial intelligence, machine learning and large-scale data science analysis from the ground up.
Expert Support for Faculty and Researchers
The Institute for Data Engineering and Science (IDEaS) and the College of Computing house the Center for Artificial Intelligence in Science and Engineering (ARTISAN) group. This team has collective experience in working with national computational, cloud, commercial and institutional resources for computational activities, and decades of experience in scientific tools that aid in assisting both teaching and research faculty. Nexus is the next logical step, bringing together everything they’ve learned to build a national resource optimized for the future of AI-driven science.
Principal Research Scientist for the ARTISAN team, Suresh Marru, highlighted the need for this new resource, “AI is a core part of the Nexus vision. Today, researchers often spend more time setting up experiments, managing data, or figuring out how to run jobs on remote clusters than doing science. With Nexus, we’re flipping that script. By embedding AI into the platform, we help automate routine tasks, suggest optimal ways to run simulations, and even assist in generating input or analyzing results. This means researchers can move faster from question to insight. Instead of wrestling with infrastructure, they can focus on discovery.”
An Accessible AI Resource for GT & US Scientific Research
90% of Nexus capacity will be made available to the national research community through the NSF Advanced Computing Systems & Services (ACSS) program. Researchers from across the country, at universities, labs, and institutions of all sizes, will have access to this next-generation AI-ready supercomputer. For Georgia Tech research faculty and staff, the new system has multiple benefits:
- 10% of the time on the machine will be available for use by Georgia Tech researchers
- Nexus will allow GT researchers a chance to try out the latest hardware for AI computing
- Thanks to cyberinfrastructure tools from the ARTISAN group, Nexus will be easier to access than previous NSF supercomputers
Interim Executive Director of IDEaS and Regents' Professor David Sherrill notes, "Nexus brings Georgia Tech's leadership in research computing to a whole new level. It will be the first NSF Category I Supercomputer hosted on Georgia Tech's campus. The Nexus hardware and software will boost research in the foundations of AI, and applications of AI in science and engineering."

These ‘chillers’ on the roof of a data center in Germany, seen from above, work to cool the equipment inside the building. AP Photo/Michael Probst
Artificial intelligence is growing fast, and so are the number of computers that power it. Behind the scenes, this rapid growth is putting a huge strain on the data centers that run AI models. These facilities are using more energy than ever.
AI models are getting larger and more complex. Today’s most advanced systems have billions of parameters, the numerical values derived from training data, and run across thousands of computer chips. To keep up, companies have responded by adding more hardware, more chips, more memory and more powerful networks. This brute force approach has helped AI make big leaps, but it’s also created a new challenge: Data centers are becoming energy-hungry giants.
Some tech companies are responding by looking to power data centers on their own with fossil fuel and nuclear power plants. AI energy demand has also spurred efforts to make more efficient computer chips.
I’m a computer engineer and a professor at Georgia Tech who specializes in high-performance computing. I see another path to curbing AI’s energy appetite: Make data centers more resource aware and efficient.
Energy and Heat
Modern AI data centers can use as much electricity as a small city. And it’s not just the computing that eats up power. Memory and cooling systems are major contributors, too. As AI models grow, they need more storage and faster access to data, which generates more heat. Also, as the chips become more powerful, removing heat becomes a central challenge.

Data centers house thousands of interconnected computers. Alberto Ortega/Europa Press via Getty Images
Cooling isn’t just a technical detail; it’s a major part of the energy bill. Traditional cooling is done with specialized air conditioning systems that remove heat from server racks. New methods like liquid cooling are helping, but they also require careful planning and water management. Without smarter solutions, the energy requirements and costs of AI could become unsustainable.
Even with all this advanced equipment, many data centers aren’t running efficiently. That’s because different parts of the system don’t always talk to each other. For example, scheduling software might not know that a chip is overheating or that a network connection is clogged. As a result, some servers sit idle while others struggle to keep up. This lack of coordination can lead to wasted energy and underused resources.
A Smarter Way Forward
Addressing this challenge requires rethinking how to design and manage the systems that support AI. That means moving away from brute-force scaling and toward smarter, more specialized infrastructure.
Here are three key ideas:
Address variability in hardware. Not all chips are the same. Even within the same generation, chips vary in how fast they operate and how much heat they can tolerate, leading to heterogeneity in both performance and energy efficiency. Computer systems in data centers should recognize differences among chips in performance, heat tolerance and energy use, and adjust accordingly.
Adapt to changing conditions. AI workloads vary over time. For instance, thermal hotspots on chips can trigger the chips to slow down, fluctuating grid supply can cap the peak power that centers can draw, and bursts of data between chips can create congestion in the network that connects them. Systems should be designed to respond in real time to things like temperature, power availability and data traffic.
Break down silos. Engineers who design chips, software and data centers should work together. When these teams collaborate, they can find new ways to save energy and improve performance. To that end, my colleagues, students and I at Georgia Tech’s AI Makerspace, a high-performance AI data center, are exploring these challenges hands-on. We’re working across disciplines, from hardware to software to energy systems, to build and test AI systems that are efficient, scalable and sustainable.
Scaling With Intelligence
AI has the potential to transform science, medicine, education and more, but risks hitting limits on performance, energy and cost. The future of AI depends not only on better models, but also on better infrastructure.
To keep AI growing in a way that benefits society, I believe it’s important to shift from scaling by force to scaling with intelligence.![]()
This article is republished from The Conversation under a Creative Commons license. Read the original article.
News Contact
Author:
Divya Mahajan, assistant professor of Computer Engineering, Georgia Institute of Technology
Media Contact:
Shelley Wunder-Smith
shelley.wunder-smith@research.gatech.edu

An illustration representing a doctor working with an AI-powered health device.
In the morning, before you even open your eyes, your wearable device has already checked your vitals. By the time you brush your teeth, it has scanned your sleep patterns, flagged a slight irregularity, and adjusted your health plan. As you take your first sip of coffee, it’s already predicted your risks for the week ahead.
Georgia Tech researchers warn that this version of AI healthcare imagines a patient who is "affluent, able-bodied, tech-savvy, and always available." Those who don’t fit that mold, they argue, risk becoming invisible in the healthcare system.
The Ideal Future
In their study, published in the Proceedings of the ACM Conference on Human Factors in Computing Systems, the researchers analyzed 21 AI-driven health tools, ranging from fertility apps and wearable devices to diagnostic platforms and chatbots. They used sociological theory to understand the vision of the future these tools promote — and the patients they leave out.
“These systems envision care that is seamless, automatic, and always on,” said Catherine Wieczorek, a Ph.D. student in human-centered computing in the School of Interactive Computing and lead author of the study. “But they also flatten the messy realities of illness, disability, and socioeconomic complexity.”
Four Futures, One Narrow Lens
During their analysis, the researchers discovered four recurring narratives in AI-powered healthcare:
- Care that never sleeps. Devices track your heart rate, glucose levels, and fertility signals — all in real time. You are always being watched, because that’s framed as “care.”
- Efficiency as empathy. AI is faster, more objective, and more accurate. Unlike humans, it doesn’t get tired or biased. This pitch downplays the value of human judgment and connection.
- Prevention as perfection. A world where illness is avoided through early detection if you have the right sensors, the right app, and the right lifestyle.
- The optimized body. You’re not just healthy, you’re high-performing. The tech isn’t just treating you; it’s upgrading you.
“It’s like healthcare is becoming a productivity tool,” Wieczorek said. “You’re not just a patient anymore. You’re a project.”
Not Just a Tool, But a Teammate
This study also points to a critical transformation in which AI is no longer just a diagnostic tool; it’s a decision-maker. Described by the researchers as “both an agent and a gatekeeper,” AI now plays an active role in how care is delivered.
In some cases, AI systems are even named and personified, like Chloe, an IVF decision-support tool. “Chloe equips clinicians with the power of AI to work better and faster,” its promotional materials state. By framing AI this way — as a collaborator rather than just software — these systems subtly redefine who, or what, gets to be treated.
“When you give AI names, personalities, or decision-making roles, you’re doing more than programming. You’re shifting accountability and agency. That has consequences,” said Shaowen Bardzell, chair of Georgia Tech’s School of Interactive Computing and co-author of the study.
“It blurs the boundaries,” Wieczorek noted. “When AI takes on these roles, it’s reshaping how decisions are made and who holds authority in care.”
Calculated Care
Many AI tools promise early detection, hyper-efficiency, and optimized outcomes. But the study found that these systems risk sidelining patients with chronic illness, disabilities, or complex medical needs — the very people who rely most on healthcare.
“These technologies are selling worldviews,” Wieczorek explained. “They’re quietly defining who healthcare is for, and who it isn’t.”
By prioritizing predictive algorithms and automation, AI can strip away the context and humanity that real-world care requires.
“Algorithms don’t see nuance. It’s difficult for a model to understand how a patient might be juggling multiple diagnoses or understand what it means to manage illness, while also navigating other important concerns like financial insecurity or caregiving. They are predetermined inputs and outputs,” Wieczorek said. “While these systems claim to streamline care, they are also encoding assumptions about who matters and how care should work. And when those assumptions go unchallenged, the most vulnerable patients are often the ones left out.”
AI for ALL
The researchers argue that future AI systems must be developed in collaboration with those who don’t fit in the vision of a “perfect patient.”
“Innovation without ethics risks reinforcing existing inequalities. It’s about better tech and better outcomes for real people,” Bardzell said. “We’re not anti-innovation. But technological progress isn’t just about what we can do. It’s about what we should do — and for whom.”
Wieczorek and Bardzell aren’t trying to stop AI from entering healthcare. They’re asking AI developers to understand who they’re really serving.
Funding:
This work was supported by the National Science Foundation (Grant #2418059).
News Contact
Michelle Azriel, Sr. Writer-Editor

Bigfoot vlogs are an example of AI-generated content that has gained attention for its use of hyperrealistic storytelling and digital personas in online media.

From Bigfoot vlogs to algorithmically created personas, hyperrealistic AI content is redefining the boundaries of digital creators. These influencers are entirely virtual personas created using generative AI tools that simulate human features, voices, and behaviors. They post lifestyle content, interact with followers, and even secure brand endorsements — all without existing in the physical world. As these technologies grow more widely available and their results more believable, specialists caution that we are moving into a new age where the line separating fiction from reality is becoming increasingly blurred.
The Rise of Synthetic Creativity
Experts at Georgia Tech say the surge in AI hyperrealism — content that mimics human emotion, speech, and appearance with uncanny precision — is both a technological marvel and a societal challenge.
“AI does not have emotions as we understand them in humans, but it knows how to mimic emotional speech,” said Mark Riedl, professor in the School of Interactive Computing. “Once we understand that AI is mimicking us, it is easy to understand how they can create believable outputs that sound authentic.”
Riedl points to the democratization of video creation as a major shift. “AI video generation tools and the ability to bypass traditional content channels and post directly to social media have opened up the floodgates,” he said.
Recent examples include synthetic influencers such as Nobody Sausage, a digitally animated character that has attracted over 30 million followers across multiple social media platforms through short-form dance videos and brand collaborations. On platforms like Character.AI, users engage with millions of virtual personas designed to simulate conversation and personality traits. These AI-generated figures are reshaping how audiences interact with content, marketing, and identity across Instagram, TikTok, and other social media channels.
Mental Health and the Reality Gap
Munmun De Choudhury, professor in the School of Interactive Computing, warns that hyperreal AI content can distort users’ perception of reality, especially among vulnerable populations.
“This distortion can fuel anxiety, exacerbate body image and self-comparison issues, and contribute to a broader erosion of epistemic trust — our basic belief in what others present as true,” she said.
Her research shows that social media already blurs the line between authentic self-expression and performative identity. Hyperreal AI content — from deepfakes to emotionally resonant synthetic personas — further complicates users’ ability to evaluate what is real or trustworthy. Adolescents and those facing mental health challenges may be especially susceptible.
“Individuals experiencing stress or social isolation may be more prone to believe deepfakes,” De Choudhury explained. “Such content often reinforces existing beliefs or fills gaps in social connection.”
The AI content challenges our understanding of authenticity, trust, and digital identity. It also raises questions about consent, misinformation, and the psychological effects of interacting with synthetic personas. Gen Z users, she notes, often judge AI content by emotional resonance rather than factual accuracy, while older users may struggle to detect synthetic cues altogether.
Platforms, Persuasion, and Misinformation
Riedl emphasizes that AI storytelling tools can be used to sway public opinion through “narrative transportation,” a psychological phenomenon in which audiences become immersed in a story and are less likely to question its truth.
“Storytelling is a means of persuasive communication,” he said. “Our brains are attuned to stories in a way that can bypass critical thinking.”
Recent incidents highlight the changing landscape. Deepfakes of public figures such as Taylor Swift and Tom Hanks have surged in 2025, with over 179 incidents in the first four months of the year alone — surpassing all of 2024. These deepfakes range from humorous impersonations to fraudulent and explicit content, raising ethical and legal concerns about identity misuse and misinformation. Riedl notes that video misinformation has historically been harder to produce but is now easier and more likely to be tailored to niche audiences.
Social media companies face mounting pressure to take action. De Choudhury argues that labeling AI-generated content is necessary but insufficient. “Platforms must invest in user-centered design, digital literacy interventions, and transparency about how algorithms surface such content,” she said.
The stakes are especially high in mental health communities, where authenticity and lived experience are critical. “Users often feel overwhelmed or deceived when they encounter synthetic content without clear cues of its artificial origin,” she added.
Governance in a Globalized AI Era
Milton Mueller, professor in the Jimmy and Rosalynn Carter School of Public Policy, argues that regulation may be ineffective or even counterproductive in a decentralized digital ecosystem.
“Generative AI is part of a globalized and distributed digital ecosystem,” Mueller said. “So, which regulatory authority are you talking about, and how does it gain the leverage needed to control the outputs?”
While the EU’s AI Act mandates labeling and imposes steep fines, U.S. efforts remain fragmented. The Federal Communications Commission has made AI-generated voices in robocalls illegal, with entities facing fines, and several states are pushing for watermarking and criminal penalties for political deepfakes. But experts warn that First Amendment protections complicate enforcement.
Mueller cautions that governments are already using AI as a geopolitical tool, which could undermine global cooperation and lead to strategic escalation. “Instead of freely trading data and establishing common rules, governments are asserting digital sovereignty,” he said.
He advocates for addressing AI-generated misinformation through decentralized governance, public debate, and media literacy, rather than centralized regulation or automated controls, emphasizing that content moderation should be guided by open processes and existing legal remedies applied after the fact.
As AI-generated content becomes more sophisticated and widespread, researchers say the challenge lies not only in technological safeguards but in how society adapts. Experts at Georgia Tech emphasize the need for transparency, interdisciplinary collaboration, and public engagement. The future of hyperreal media, they say, will depend on how well platforms, policymakers, and users navigate its risks and possibilities.
News Contact

Research Scientist Amanda Meng

Amanda Meng
As technology becomes increasingly intertwined with all aspects of society, more researchers are interested in how to use these tools to advance social equity.
One of these researchers is Amanda Meng, senior research scientist in the School of Computer Science (SCS). The overarching theme in Meng’s work is the relationship between power and data and how different social groups can make use of data to shift power.
As the only social scientist in SCS, Meng sees her role as an “important and potentially powerful interdisciplinary connection.”
Connecting Social Justice with Data
Although focused on political and social change, Meng’s work has always had links to technology.
After completing her undergraduate education at Georgia Tech, Meng joined the Peace Corps, where she served in the Dominican Republic. She spent two years there working to improve computer literacy in schools and create community computer labs.
Meng said her time in the Peace Corps made her interested in how communities advocated for themselves. She explored this idea further while completing her Ph.D. from the Georgia Tech Sam Nunn School of International Affairs.
With her Ph.D. in hand, Meng was hired as a research scientist in SCS, working under Professor Ellen Zegura and School of Interactive Computing Professor Carl DiSalvo on civic data projects based in Atlanta.
This experience made her curious about the interaction between data literacy and civic literacy.
“We live in such a data-fied society that a lot of advocacy work often does involve data because to make your claims legitimate, policy makers want to see and understand the data,” she said.
Following a brief stint in the private sector as a data consultant, Meng returned to SCS, this time as a research scientist working on IODA (Internet Outage Detection and Analysis) with Associate Professor Alberto Dainotti. IODA is a research project and online platform that provides real-time measurements on global internet connectivity.
In her contribution to the IODA project, Meng aims to improve the usability of IODA, particularly by users affected by government-ordered shutdowns, by developing IODA users’ internet measurement literacy. Currently, IODA provides the most granular, near-real-time data on Internet infrastructure connectivity. Meng uses this data to collaborate with global advocacy groups to publish reports detailing IODA’s measurements alongside its sociopolitical context. Meng said the eventual goal of her work with IODA is for others to know how to use the platform to monitor for events and advocate against shutdowns.
“The platform is really only as successful as its userbase is at understanding, making use, and acting on its data,” Meng said.
In the past year, Meng was awarded her first grant as principal investigator. The grant uses Aggie, an open-source tool developed at Tech that aggregates content from the internet.
Previously, Aggie has been used to monitor elections on social media. Meng said she wants to explore using it to monitor internet shutdowns or censorship events. She is currently conducting a pilot study to test the system, which will determine whether Aggie offers a more collaborative and coordinated way to monitor connectivity across measurement and social media data.
The Role of a Research Scientist
As a research scientist, almost all of Meng’s work is oriented toward research. This includes working on proposals and existing grants, as well as advising students.
“We love to involve students in our research,” she said. “We aren’t just here to do research. We are here to involve students in research so they can learn and develop domain skills and research skills.”
Since 2024, Meng has served on the School Advisory Committee in SCS. She says it’s important to have research faculty in service roles, as they have a different set of needs in their position.
“Through the funding we can apply for, the research we do, and the work we do with students, we are an important multiplier for the work that the School wants to cultivate,” Meng said.
Community Driven
Even as a Ph.D. student, Meng said she wanted to contribute to local community groups. An important value she learned in the Peace Corps was to be an active participant in the community she lived in.
Meng started getting involved in a housing justice project in Atlanta’s Westside neighborhood that was collecting data related to their mission. They soon discovered that some residents’ data was more accurate than official records because they lived there.
“We also learned it’s not all about impacting legislation,” Meng said. “It’s about mobilizing resources within the community, and the fact that data could be used to do that was an important finding, and it’s something that I want to continue to draw out with data and AI.”
Meng has continued to work with the group from that project and wants to continue ethnographic research into how data and AI are used to create change.
“AI could have the ability to consolidate power in the hands of those who develop closed-source models," Meng said. "It’s important to study the entities that are developing AI as much as we study the communities that might make use of or be most minoritized by AI."
News Contact
Morgan Usry, School of Computer Science Communications Officer